Introduction
Object detection, the ability of a computer vision system to identify and locate objects within an image or video, has revolutionized fields from autonomous driving to medical imaging. Among the plethora of object detection algorithms, YOLO (meaning You Only Look Once) stands out for its remarkable speed and efficiency, making it a cornerstone for real-time applications. In this blog post, we do a brief dissection of the YOLO process, while exploring its inner workings and highlighting its significance in the world of computer vision. The content has been written to be clear enough for all levels.
From Image to Insight: The YOLO Pipeline
The YOLO process can be visualized as a pipeline, transforming a raw image into a set of meaningful insights about the objects present within it. Let’s break down each stage:
- Input Image: The journey begins with the input image – the raw visual data that we want to analyze. This could be a static image or a frame extracted from a video stream.
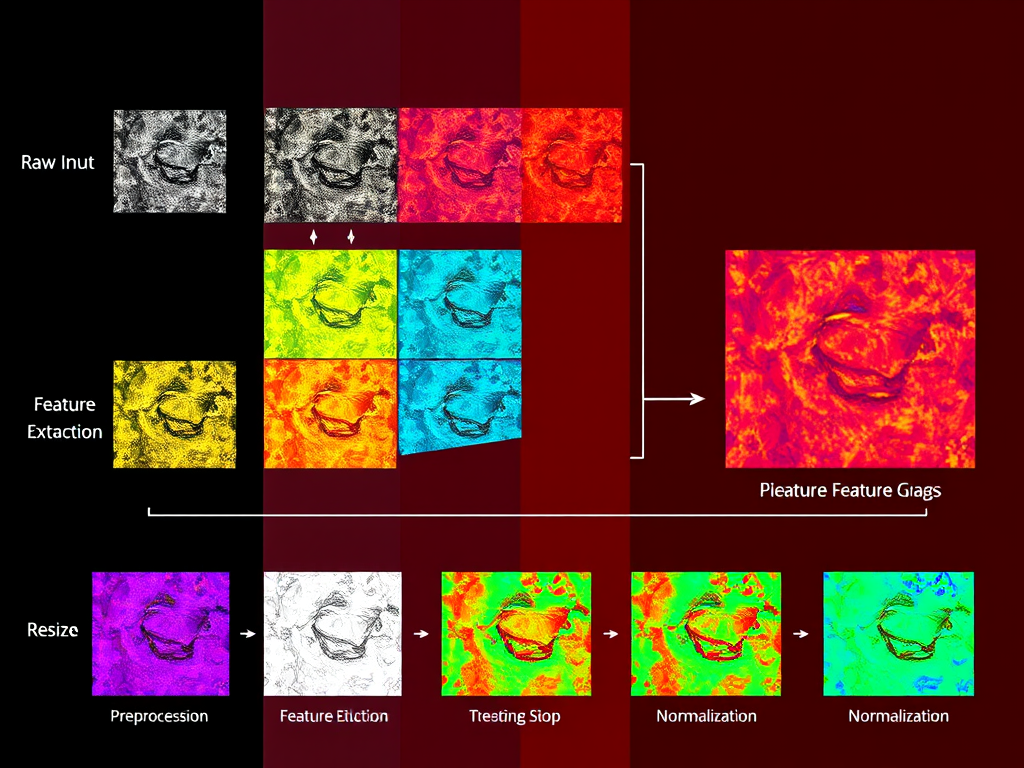
- Preprocessing: Before the image can be fed into the neural network, it undergoes a series of preprocessing steps. These are crucial for optimizing performance and ensuring compatibility with the model. Two primary operations are involved:
- Resizing: YOLO models expect a fixed input size. The input image is resized to match this requirement, typically a square image (e.g., 416×416, 608×608). This standardization ensures consistent processing.
- Normalization: Pixel values, usually ranging from 0 to 255, are normalized to a range between 0 and 1. This is achieved by dividing each pixel value by 255. Normalization aids in faster convergence during training and improves the stability of the model.
- Feature Extraction (Backbone): This is where the magic begins. A Convolutional Neural Network (CNN), often referred to as the “backbone,” takes the preprocessed image as input. This backbone is a pre-trained network, meaning it has already learned to recognize general image features from a massive dataset (like ImageNet). Common backbones include Darknet (used in earlier YOLO versions), ResNet, and others. The backbone’s role is to extract a rich set of features from the image, capturing both low-level details (edges, textures) and high-level concepts (object shapes, patterns).
- Feature Maps: The output of the backbone is a set of feature maps. These are essentially compressed representations of the original image, highlighting the most salient features. They are smaller in size than the input image but contain crucial information about the spatial arrangement and characteristics of objects. The feature maps are multi-layered, with each layer capturing increasingly abstract and complex features.
- Detection (Head): This stage is where the actual object detection happens. YOLO employs a “head” that operates on the feature maps to perform three key tasks:
- Bounding Box Regression: The head predicts the location and size of bounding boxes around potential objects. These boxes are defined by their center coordinates, width, and height. The regression task aims to refine these parameters to accurately enclose the objects.
- Class Prediction: For each bounding box, the head predicts the class label of the object it contains. This could be “person,” “car,” “bicycle,” or any other category the model has been trained to recognize. The prediction is typically a probability distribution over all possible classes.
- Confidence Score Prediction: The head also predicts a confidence score for each bounding box. This score indicates how certain the model is that the box actually contains an object and not just background. A high confidence score suggests a strong presence of an object.
- Postprocessing: The raw outputs from the detection head undergo postprocessing to refine the results and eliminate redundancies. The most important step here is:
- Non-Maximum Suppression (NMS): YOLO often predicts multiple bounding boxes for the same object. NMS is a crucial algorithm that filters out these overlapping boxes, keeping only the one with the highest confidence score. It works by iteratively suppressing boxes that have a high overlap (measured by Intersection over Union or IoU) with the box of highest confidence.
- Output: The final output of the YOLO process consists of a set of detected objects, each characterized by:
- Bounding Box: The coordinates of the box enclosing the object.
- Class Label: The predicted category of the object.
- Confidence Score: The model’s confidence in the detection.
YOLO's Innovation: Speed and Efficiency
The key innovation of YOLO lies in its approach to object detection. Unlike earlier methods that treated detection as a multi-stage process (e.g., region proposal followed by classification), YOLO frames the task as a single regression problem. It divides the input image into a grid of cells, and for each cell, it predicts bounding boxes and class probabilities. This “one-shot” approach allows YOLO to process images much faster than traditional methods, making it suitable for real-time applications.
Evolution of YOLO: From YOLOv1 to YOLOv7 and Beyond
Since its inception, YOLO has undergone several iterations, each improving upon its predecessor. YOLOv1, the original version, introduced the one-stage detection paradigm. Subsequent versions (YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOv7) have incorporated various enhancements, including:
- Improved Backbone Architectures: Adopting more powerful backbones like Darknet-53 and ResNet has led to better feature extraction and increased accuracy.
- Anchor Boxes: Introducing anchor boxes, pre-defined shapes and sizes, has helped YOLO to better handle objects of different aspect ratios.
- Multi-Scale Predictions: Predicting bounding boxes at multiple scales has improved the detection of both small and large objects.
- Focal Loss: Addressing class imbalance issues during training has further boosted accuracy.
Applications of YOLO: Transforming Industries
YOLO’s speed and accuracy have made it a valuable tool in a wide range of applications:
- Autonomous Driving: Real-time object detection is crucial for self-driving cars to perceive their environment and make informed decisions.
- Surveillance: YOLO can be used to monitor video feeds for suspicious activities or to track individuals.
- Robotics: Enabling robots to perceive and interact with their surroundings.
- Medical Imaging: Assisting in the detection of tumors or other anomalies in medical scans.
- Retail Analytics: Tracking customer behavior in stores to optimize product placement and improve sales.
Conclusion: The Future of Real-Time Object Detection
YOLO has undeniably revolutionized the field of object detection, paving the way for real-time applications that were previously unimaginable. Its clever design and continuous evolution have made it a leading algorithm in the domain. As research continues and new versions of YOLO emerge, we can expect even greater advancements in speed, accuracy, and efficiency, further expanding the possibilities of computer vision. The future of real-time object detection is bright, and YOLO is at the forefront of this exciting journey.
References
- Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE conference on computer vision and pattern recognition, 779-788.
- Redmon, J., & Farhadi, A. (2017). Yolov2: Better, faster, stronger. Proceedings of the IEEE conference on computer vision and pattern recognition, 29-37.
- Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767.
- Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
- Jocher, G. (2020). YOLOv5. GitHub Repository.
- Wang, C.Y., Bochkovskiy, A., & Liao, H.Y.M. (2022). YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696.
Start Learning Python Now
If you would like to learn how to use YOLO someday, why not start with learning the Python programming language now. You can register on our (currently) free course. It introduces you to the basic concepts that you will need to jump onto the bandwagon of computer programming, and especially, into the exciting world of Artificial Intelligence (AI) and Computer Vision.
Start small, take your time and learn the concepts. That’s how we started, and it paid off. It paid off by enabling us to assimilate and entrench the basic concepts that we need for learning to code.
You can register, log in, read through the concepts, read the exercises and solutions, and take a break (quite important when learning programming). You would also be able to call attention to the expert tutor to give you some guidelines. Get onto the course now by clicking on this link Python for Beginners


